Cuprins
- 1. Capitolul 1 - Introducere 3
- 1.1. Obiective 4
- 1.2. Contribuții originale 4
- 1.3. Structura lucrării 5
- 2. Capitolul II - Metode de identificare a similarităților între documente 6
- 2.1. Analiza similitudinii 6
- 2.2. Compararea documentelor la nivel de propoziție 8
- 2.3. Compararea documentelor folosind factori de corelație 9
- 2.4. Clasificare și amprentare 11
- 2.4.1. Clasificarê 11
- 2.4.2. Amprentare 13
- 3. Capitolul III - Tehnologii Web 16
- 3.1. PHP, Apache și MySQL 16
- 3.2. HTML, CSS și jQuery 18
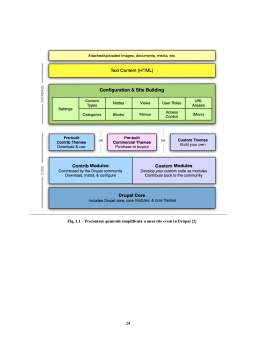
- 3.3. Drupal 20
- 3.3.1. Noțiuni de bază 21
- 3.3.2. Teme Drupal 23
- 4. Capitolul IV - Aplicație de detectare a plagiatului 25
- 4.1. Preprocesarea documentelor 26
- 4.2. Compararea documentelor 27
- 4.3. Funcționalități ale aplicației 30
- 4.4. Analiza rezultatelor 36
- 5. Capitolul V - Concluzii 38
- 5.1. Activități propuse 39
- 6. Bibliografie 40
Extras din licență
1. Capitolul 1 - Introducere
A plagia înseamnă a folosi sau a copia parțial ideile altcuiva fără a cita autorul original, sau conform [6], „a lua, a fura ideile, expresiile, invențiile cuiva și a le prezenta drept creații proprii; a publica pe numele său fragmente din lucrarea altuia; a comite un furt literar”.
Termenul „plagiere” își are originea în cuvântul latin „plagium”, care în secolul I însemna răpirea unui sclav sau a unui copil, iar plagiatorul („plagiarius”) însemna jefuitor, răpitor sau om care ajuta infractorii să se ascundă. În anul 1601, termenul „plagiere” a fost introdus în limba engleză de dramaturgul Ben Jonson, pentru a descrie furtul literar. [10]
Într-adevăr, cuvântul „plagiere” este sinonim cu furtul, dar acțiunea de a plagia este mai gravă întrucât persoana care plagiază fură ceva unic: ideile, creativitatea și personalitatea autorului - ceea ce îl reprezintă de fapt.
În ziua de azi, plagiatul este destul de comun printre studenți, profesori și cercetători și devine o problemă din ce în ce mai serioasă. Un factor care contribuie la această situație este accesul foarte ușor la Internet, adică la numeroase publicații online pe care studenții le găsesc și le copiază sau le modifică cu ușurință. Internetul cuprinde cel mai mare număr de articole și informații publice online, iar o mare parte din această informație este publicată în mai mult de o singură locație. O căutare pe Internet a unui subiect returnează rezultate aproape identice în zeci de locații diferite.
În urma studiilor s-a descoperit că plagiatul în universități a crescut semnificativ în ultima jumătate de secol, ceea ce a afectat calitatea educației primite de studenți. Cadrele universitare știu că pentru a avea cunoștințe bogate în orice domeniu, studenții au nevoie de informația furnizată de paginile web, însă aceștia sunt tentați să utilizeze informațiile găsite pentru a „practica” plagiatul. Informațiile trebuie utilizate în mod legal și moral, adică o persoană trebuie să știe cum să folosească informația: cum să o găsească, cum să o structureze, să o evalueze și să o modeleze din propriul punct de vedere. Acest lucru constituie o competență pe care orice student absolvent ar trebui să o aibă, însă din cauza faptului că nu există sisteme de detectare a plagiatului în fiecare universitate, cei mai mulți studenți preferă să copieze decât să scrie lucrări originale.
Detectarea plagiatului poate ajuta cadrele universitare să îmbunătățească calitatea educației studenților. De aceea, acest subiect a fost dezbătut în ultimii ani atât în universități, cât și în cercurile politice. Au fost dezvoltate numeroase aplicații comerciale de detectare a plagiatului, care utilizează diferite metode. Majoritatea aplicațiilor sunt capabile să identifice fraze plagiate în care s-a modificat ordinea cuvintelor, s-au înlocuit cuvintele cu sinonimele lor, propoziții scurte legate într-o frază sau fraze împărțite în propoziții scurte etc.
1.1. Obiective
Obiectivele generale ale lucrării de față sunt:
- definirea plagiatului și descrierea tehnicilor de plagiere
- prezentarea diverselor metode de identificare a similarităților dintre texte
- dezvoltarea unei aplicații care compară documente și identifică care dintre acestea sunt plagiate
- prezentarea tehnologiilor utilizate pentru realizarea aplicației.
Scopul principal este de a readuce tehnicile de învățare pe care Internetul le-a schimbat prin furnizarea atâtor resurse ușor de găsit și de copiat. Pentru a realiza scopul propus, am dezvoltat o aplicație web de detectare a plagiatului, care, printr-o interfață user-friendly, le permite studenților să se înregistreze și să își depună lucrările atribuite, iar cadrelor didactice să identifice, pentru fiecare lucrare în parte, secvențele suspecte și documentele sursă din care acestea provin.
1.2. Contribuții originale
În general, un student care plagiază lucrări existente pentru a realizeaza un eseu, copiază porțiuni mari de text pe care le modifică (uneori) prin reordonarea sau ștergerea unor cuvinte, ca să pară originale. Ulterior, studentul adaugă paragrafe originale pentru a finaliza tema atribuită. Metoda propusă în această lucrare, numită SimilarDocumentsDetection (SimDD), a fost creată cu scopul de a identifica astfel de documente.
Ideea de bază a metodei SimDD este că un paragraf poate fi considerat plagiat dacă mai mult de 3 dintre termenii din acesta au fost găsiți la distanțe relativ apropiate în documentul original. SimDD verifică dacă un document suspect DP este plagiat comparând cuvintele cheie din acesta cu toate cuvintele cheie din celelalte documente din baza de date și astfel identifică (i) propozițiile copiate, (ii) propozițiile care au fost create prin unirea sau despărțirea unor propoziții din documentul original și (iii) propozițiile în care cuvintele au fost amestecate.
1.3. Structura lucrării
În continuare, lucrarea este structurată pe 3 capitole, după cum urmează.
În Capitolul 2 - „Metode de identificare a similarităților între documente” - sunt evaluate mai multe tehnici de detectare a plagiatului dezvoltate până în prezent din diverse lucrări. Metodele prezentate sunt diferite din multe puncte de vedere, prezentând abordări originale pentru fiecare aspect ce trebuie studiat în procesul de detectare a plagiatului: stocarea documentelor într-o bază de date, preprocesarea documentelor în vederea comparării rapide a textelor, vizualizarea rezultatelor etc.
Capitolul 3 - „Tehnologii Web” - prezintă tehnologiile utilizate pentru dezvoltarea soft-ului. Pentru a crea o aplicație web, este nevoie de tehnologii pentru stocarea informațiilor, pentru partea de logică a aplicației, care oferă dinamism paginilor web și pentru partea de prezentare, adică tot ce ține de interfață.
În Capitolul 4 - „Aplicație de detectare a plagiatului” - este detaliată metoda propusă și sunt prezentate deciziile care au fost luate pentru implementarea algoritmului de comparare a textelor. De asemenea, capitolul prezintă funcționalitățile aplicației de detectare a plagiatului și o analiză a rezultatelor obținute.
Ultimul capitol - „Concluzii” - cuprinde concluziile generale ale studiului realizat și activitățile propuse pentru îmbunătățirea aplicației.
Bibliografie
[1] Arnold D. Robbins: GAWK: Effective AWK Programming, http://www.gnu.org/software/gawk/manual/gawk.html.
[2 ] A. Chavan: Drupal Ingredients Diagram: Let's start at the very beginning..., http://www.urbaninsight.com/comment/2206.
[3] Benjamin Melançon, Jacine Luisi, Károly Négyesi, Greg Anderson, Bojhan Somers, Stéphane Corlosquet, Stefan Freudenberg, Michelle Lauer, Ed Carlevale, Florian Lorétan, Dani Nordin, Ryan Szrama, Susan Stewart, Jake Strawn, Brian Travis, Dan Hakimzadeh, Amye Scavarda, Albert Albala, Allie Micka, Robert Douglass, Robin Monks, Roy Scholten, Peter Wolanin, Kay VanValkenburgh, Greg Stout, Kasey Qynn Dolin, Forest Mars, Sam Boyer, Mike Gifford and Claudina Sarahe: Definitive Guide To Drupal, Apress, New York, 2011.
[4] Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze: An Introduction to Information Retrieval, Cambridge University Press, Cambridge, England, 2010.
[5] Daniel R. White and Mike S. Joy: Sentence-Based Natural Language Plagiarism Detection, ACM Journal of Educational Resources, 4 (2004), 1-20.
[6] Dex Online, definiție a plagia, „Dicționarul Explicativ al limbii române, ediția a II-a, DEX '98”, Academia Română, Institutul de Lingivstică „Iorgu Iordan”, Ed. Univers Enciclopedic, 1998, http://dexonline.ro/definitie/plagia.
[7] Drupal community: Drupal.org Community Documentation, https://api.drupal.org/api/drupal/includes%21module.inc/group/hooks/7.
[8] Felipe Felipe Bravo-Marquez, Gaston L'Huillier, Sebastiîn A. Ríos, Juan D. Velîsquez: A Text Similarity Meta-Search Engine Based on Document Fingerprints and Search Results Records, Proceedings of the 2011 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology, 1 (2011), 146-153.
[9] Introna, Lucas and Hayes, Niall: „Plagiarism Detection Systems and International Students: Detecting plagiarism, copying or learning?” in Student Plagiarism in an Online World: Problems and Solutions. Idea Group Publishing, Hershey and London, 2007, pp. 108-122
[10] Jack Lynch: The Perfectly Acceptable Practice of Literary Theft: Plagiarism, Copyright, and the Eighteenth Century, http://www.writing-world.com/rights/lynch.shtml.
[11] Jason Lengstorf: PHP for Absolute Beginners, Apress, New York, 2009.
[12] Jonathan Chaffer, Karl Swedberg: Learning jQuery Third Edition, Packt Publishing, Birmingham, UK, 2009.
[13] Nathaniel Gustafson, Maria Soledad Pera, Yiu-Kai Ng: Nowhere to Hide: Finding Plagiarized Documents Based on Sentence Similarity, Proceedings of the 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, December (2008), 690-696.
[14] Mary Bellis: The History of the Internet, http://inventors.about.com/od/istartinventions/a/internet.htm.
[15] M. Pera and Y.-K. Ng.: Utilizing Phrase-Similarity Measures for Detecting and Clustering Informative RSS News Articles, Integrated Computer-Aided Engineering, 15 (2008), 331-350.
[16] M.V. Ramakrishna and J. Zobel: Performance in practice of string hashing function, Proceedings of the Fifth International Conference on Database Systems for Advanced Applications, April(1997), 178-185.
[17] MySQL 3.23, 4.0, 4.1 Reference Manual, http://dev.mysql.com/doc/refman/4.1/en/history.html.
[18] Robert Schifreen: How to create Web sites and applications with HTML, CSS, Javascript, PHP and MySQL, Oakworth Business Publishing Ltd, UK, 2009.
[19] - Shanmugasundaram Harihara: Automatic Plagiarism Detection Using Similarity Analysis, The International Arab Journal of Information Technology, 4 (2012), 322 326.
[20] - Timothy C. Hoad and Justin Zobel: Methods for Identifying Versioned and Plagiarized Documents, Journal of the American Society for Information Science and Technology, 54 (2003), 203-215.
[21] Witten, I.H., Moffat, A., & Bell, T.C.: Managing gigabytes: Compressing and indexing documents and images (2nd ed.), Morgan Kaufmann, San Francisco, CA, 1999.
[22] w3c: A Short History of JavaScript, http://www.w3.org/community/webed/wiki/A_Short_History_of_JavaScript.
[23] w3schools: HTML Introduction, http://www.w3schools.com/html/html_intro.asp.
Preview document










































Conținut arhivă zip
- Serviciu web pentru identificarea lucrarilor plagiate.docx
Alții au mai descărcat și

3.1.Accesul mijloacelor si al personalului pentru interventie in caz de incendiu se asigura in permanenta la toate: a) constructia unitatii cu...

Masuratorile directe de aceeasi precizie, reprezinta un volum important de lucrari, executate pe teren în cadrul activitatilor geodezice,...


Dragi studenți, Am cules pentru dumneavoastră acest material care a fost conceput de o echipă largă de profesori de la mai multe facultăți. Si...