
Extras din proiect
Pentru exemplificarea acestui algoritm vom presupune că managerul unei firme de transport doreşte să afle cum sunt grupate autoturismele pe piaţă, acesta dorind să achiziţioneze 7 laptopuri pentru societatea sa.
Managerul s-a oprit asupra a 10 autoturisme cuprinzând mărci foarte cunoscute ca:
Dacia, KIA, VW, Renault, Audi, BMW sau Colt.
Despre autoturismele respective managerul are informaţii referitoare la preţ, capacitate cilindrică, masa maximă, putere, lungime, lăţime, greutate, ehipamente suplimentare, garanţie şi număr locuri.
Pentru a proceda la gruparea acestora, managerul a întocmit o bază de date în SPSS 16.0, cu 10 variabile definite după cum urmează:
Marca – variabilă nominală, definită string, de 20 de caractere, aliniere la dreapta, ea defineşte marca autoturismului.
Preţ – variabilă de proporţie, definită numeric, de 8 caractere şi 2 zecimale, aliniere la dreapta, ea reprezintă preţul final de cumpărare a maşinii.
Capacitate cilindrică (CapCil) – variabilă de proporţie, definită numeric, de 4 caractere şi 2 zecimale, aliniere dreapta, reprezentând capacitatea cilindrică a motorului, exprimată în centrimetri cubi.
Masa maximă (MasaMax) – variabilă de proporţie, de 4 caractere, aliniere la dreapta, reprezintă masa totală maximă autorizată măsurată în kg.
Putere – variabilă de proporţie, definită numeric, de 3 caractere, aliniere la dreapta, reprezintă puterea maximă a motorului în kW.
Lungime – variabilă de proporţie, de 6 caractere şi 2 zecimale, aliniere la dreapta, reprezintă lungimea maşinii în cm.
Lăţime – variabilă de proporţie, definită numeric, de 6 caractere şi 2 zecimale, aliniere la dreapta, ea reprezintă lăţimea maşinii în cm.
Greutate – variabilă de proporţie, definită numeric, de 8 caractere şi 2 zecimale, aliniere la dreapta, reprezintă greutatea proprie a autoturismului, în kg.
Echipamente suplimentare (EchipSup) – variabilă de proporţie, definită numerică, de 1 caracter, aliniere la dreapta, reprezintă echiparea suplimentară a maşinii ( 1- DA, 2 – NU).
Garanţia – variabilă de proporţie, definită numeric, de 2 caractere, aliniere la dreapta, ea reprezintă garanţia ofertită de firma de la care cumpără în ani.
Număr locuri (NrLocuri) – variabilă de proporţie, definită numeric, de 8 caractere, aliniere la dreapta, ea reprezintă numărul de locuri pe scaune.
Baza de date astfel obţinută va fi utilizată pentru a aplica analiza grupurilor. Deoarece baza de date are 10 variabile se va utiliza prima metodă de analiză, şi anume Hierarchical Cluster Analysis.
Această procedură identifică grupurile relativ omogene de cazuri (sau variabile) după anumite caracteristici selectate, folosind un algoritm care începe cu fiecare caz (sau variabilă) într-un grup separat, combinând grupurile până rămâne unul singur. Se pot analiza variabilele netransformate sau se poate alege dintr-o varietate de transformări standardizate. Distanţa sau măsurile similare sunt generate de procedura Proximities (de proximitate). Pentru a ajuta la alegerea celei mai bune soluţii, statisticile sunt prezente în fiecare etapă.
Pentru aceasta din meniul Analyze se selectează opţiunea Clasify apoi Hierarchical Cluster Analysis. După selectarea procedurii va apărea o fereastră care permite selectarea variabilelor de grupare şi posibilitatea personalizării.
Câmpul Variable(s) permite selectarea variabilelor pentru sau după care se face gruparea. Variabilele sunt trimise în acest câmp prin intermediul săgeţii.
Câmpul Label Cases by permite selectarea variabilei ce indică numele fiecărui caz în parte. Variabila este trimisă în acest câmp prin intermediul săgeţii.
Câmpul Cluster permite alegerea modalităţii de grupare: pentru variabile sau pentru cazuri. Dacă se alege gruparea variabilelor, câmpul Label Cases by va deveni indisponibil.
Câmpul Display permite optarea pentru afişarea sau nu a statisticilor sau a graficelor.
În fereastra Variables se selectează variabilele preţ, capacitate cilindrică, masa maximă, putere, lungime, lăţime, greutate, ehipamente suplimentare, garanţie şi număr locuri. În fereastra Label cases by selectăm variabila Marca.
În câmpul Cluster bifăm cases.
În câmpul Display bifăm ambele opţiuni.
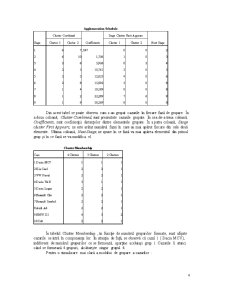
În ferestra Statistics bifăm Agglomeration Schedule, Proximity Matrix, iar în câmpul Cluster membership bifăm Range of solutions de la 2 la 4.
În ferestra Plots bifăm Dendogram, la câmpul Icicle bifăm All clusters, iar la Orientation bifăm Vertical.
În ferestra Method alegem la Cluster method Between-groups linkage, în câmpul Measure bifăm Interval şi alegem Squared Euclidean distance; în câmpul Transform values alegem Z scores şi bifăm By variables. În câmpul Transform measures nu bifăm nici o opţiune.
Preview document











Conținut arhivă zip
- Analiza Multidimensionala a Datelor.doc
Alții au mai descărcat și

I. Introducere Cunoasterea stiintifica din orice domeniu de activitate umana presupune, indiferent de natura si specificul obiectivelor concrete...

Analiza macro-mediului intreprinderii Studiul macro-mediului intreprinderii permite depasirea orizontului mediului concurential deoarece...

In era globalizarii, specialitii in domeniu vorbesc despre “intreprinderea digitala”, “intreprinderea virtuala” sau “intreprinderea mileniului...

Reforme institutionale si politice in U.E. inaintea procesului de largire. Actuala forma de organizare ce cuprinde 15 tari membre nu mai...
Te-ar putea interesa și

SISTEME INFORMAŢIONALE FINANCIAR-CONTABILE Modelarea aplicaţiilor financiar-contabile utilizând tehnici moderne de programare 1.1. Structura...

Activitatea umană include o mulţime de activităţi desfăşurate pentru a satisface diverse necesităţi, fie ele de natură materială sau spirituală....

Sistemul informational cuprinde ansamblul mijloacelor si procedurilor de preluare, clasare, stocare, prelucrare, transmitere si valorificare a...

I. Introducere Schimbarile survenite in mediul economic, modernizarea tehnologiei (automatizare si robotizare), nevoia de informatii pertinente in...

I.Descrierea datelor Analiza datelor are ca obiectiv principal extragerea informatiei relevante , semnificative care este continuta in informatia...

1. Analiza corespondențelor Scopul acestei analize este de a descrie legăturile dintre două variabile, respectiv de a studia simultan liniile și...

Analiza Cluster În cele ce urmează am încercat o clasificare a variabilelor pe clase utilizând o metodă neierarhică de clasificare, respectiv...

Introducere Sistemele Business Intelligence au un impact puternic asupra calităţii deciziilor strategice prin reducerea timpului necesar pentru a...