Extras din proiect
APLICATIA 1 – CONSUMUL DE TIGARI IN FUNCTIE DE
VENITUL INDIVIZILOR
(RLS)
Setul de date consta in indicatori pentru anii 1985-1995 pentru un numar de 528 de orase din SUA. Am obtinut astfel 528 volumul esantionului (T=528).
Cantitatea consumata este masurata prin vanzarea anuala de tigari pe locuitor in pachete, pe an fiscal. Pretul este pretul mediu la vanzari en-detail pe pachet in timpul anului fiscal, incluzand taxele (exprimat in centi). Venitul este venitul pe cap de locuitor mediu anual (in centi, pentru a putea fi corelat cu pretul pachetului de tigari, care este masurat tot in centi). Impozitul general pe vanzari este impozitul mediu, in centi pe pachet, datorita taxei / impozitului aplicat de catre stat asupra tuturor bunurilor de consum. Taxa specifica tigarilor este impozitul aplicat in exclusivitate pe tigari. Toate preturile, veniturile si taxele / impozitele sunt deflatate cu IPC si astfel, sunt in preturi constante ($ sau centi).
Doresc sa estimez in programul EVIEWS mai intai regresia dintre numarul de pachete consumate in medie si venitul pe locuitor, pentru a observa in functie de indicatorii de calitate ai modelului daca venitul reprezinta un factor regresor reprezentativ pentru model, si astfel, daca modelul este unul bun. Voi lucra in linie de comanda, nu in program. Apoi voi utiliza instrumentele puse la dispozitie de soft-ul EVIEWS pentru a intepreta mai departe calitatea modelului.
REGRESIA NrPachete=a+b*Venit+ε
INTERPRETARE STATISTICA
Observam ca R^2 are o valoare mult sub 0,5 (0,06), ceea ce semnifica o legatura foarte slaba intre numarul de pachete consumat in medie si Veniturile pe cap de locuitor. R^2 ne spune ca 6% din valoarea variabilei dependente (numarul de pachete consumat) este explicata de Venituri, care este astfel un factor nesemnificativ in regresia respectiva. Este probabil insa sa mai existe si alti factori semnificativi care ar putea explica numarul de pachete consumat in medie, factori pe care ii voi cauta cu modele de regresie ulterioare. De asemenea, si valoarea lui R^2 ajustat este foarte mica, sub 0,5, ceea ce dovedeste ca regresia, fara a fi influentata de legea numerelor mari, este de asemenea nesemnificativa. Insa acest lucru poate fi datorat diferentei mari de ordin de marime dintre cele 2 variabile, venitul pe cap de locuitor fiind de ordinul zecilor de milioane, iar numarul de pachete de ordinul sutelor, cel mult).
Abaterile standard cu care au fost estimati parametrii au o valoare mica, lucru care dovedeste calitatea modelului.
Valoarea probabilitatii corespondente testului t (p-value) este 0 pentru ambii parametri, inlcusiv coeficientul variabilei independente, deci se respinge ipoteza nula (si anume ca coeficientul ar fi 0). Astfel, reiese ca coeficientul variabilei independente este semnificativ diferit de 0, si ca variabila independenta este un factor semnificativ pentru regresarea variabilei dependente.
Testul f, care ne valideaza modelul in ansamblul sau, este de asemenea bun, probabilitatea lui f fiind 0 (aceasta valoare, in cazul regresiilor simple / cu un singur regresor, este valoarea probabilitatii testului t ridicata la patrat).
Interceptul are o valoare pozitiva, ceea ce arata ca in cazul in care valoarea Veniturilor ar fi 0, NrPachete achizitionate ar avea valoare pozitiva (ceea ce este oarecum absurd). Valoarea interceptului a fost estimata cu o abatere standard de 1,34, care este o valoare mica.
Valoarea coeficientului variabilei independente reprezinta de fapt panta dreptei de regresie, si de asemenea, reprezinta rata marginala a NrPachete achizitionate in functie de Venituri. In cazul nostru are valoare foarte mica (datorita diferentei de ordin de marime dintre cele 2 variabile) si negativa.
Valoarea statisticii Durbin-Watson este apropiata de 2 (2,02), deci nu avem autocorelarea erorilor. Astfel, statistica DW se afla in intervalul cuprins intre 1,69 si 4-1,69=2,31, deci nu avem erorile autocorelate (conform valorilor tabelate pentru statistica DW).
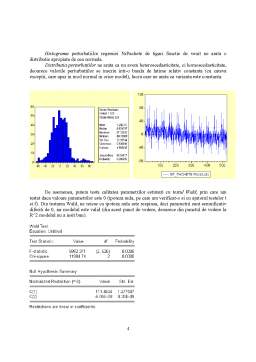
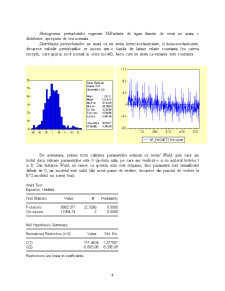
Histograma perturbatiilor regresiei NrPachete de tigari functie de venit ne arata o distributie apropiata de cea normala.
Distributia perturbatiilor ne arata ca nu avem heteroscedasticitate, ci homoscedasticitate, deoarece valorile perturbatiilor se inscriu intr-o banda de latime relativ constanta (cu cateva exceptii, care apar in mod normal in orice model), lucru care ne arata ca varianta este constanta.
De asemenea, putem testa calitatea parametrilor estimati cu testul Wald, prin care am testat daca valoare parametrilor este 0 (ipoteza nula, pe care am verificat-o si cu ajutorul testelor t si f). Din testarea Wald, ne reiese ca ipoteza nula este respinsa, deci parametrii sunt semnificativ diferiti de 0, iar modelul este valid (din acest punct de vedere, deoarece din punctul de vedere la R^2 modelul nu a iesit bun).
Preview document









































Conținut arhivă zip
- Econometrie.doc
Alții au mai descărcat și

Formularea problemei In scopul evaluarii numarului de spitale, au fost inregistrate, pe o perioada de 15 ani (2000-2014), valorile urmatoarelor...

Analiza macro-mediului intreprinderii Studiul macro-mediului intreprinderii permite depasirea orizontului mediului concurential deoarece...

In era globalizarii, specialitii in domeniu vorbesc despre “intreprinderea digitala”, “intreprinderea virtuala” sau “intreprinderea mileniului...

Introducerea seriilor în EViews Crearea unui fişier de lucru (workfile) în Eviews În urma selectării comenzii de creare a unui nou fişier de...

Reforme institutionale si politice in U.E. inaintea procesului de largire. Actuala forma de organizare ce cuprinde 15 tari membre nu mai...
Te-ar putea interesa și

INTRODUCERE Modelele econometrice analizează calitatea şi cantitatea proceselor economice şi evoluţia lor. Econometria prin caracterul său general...

INTRODUCERE Studierea mecanismelor şi a politicilor de reglare a cererii şi ofertei de forţa de muncă în perioada de tranziţie la economia de...

1. Obiectivele Econometriei Econometria are ca obiect cunoaşterea mecanismelor de desfăşurare a proceselor economice, descrise de seriile de date...

1. SCURTĂ DESCRIERE A COLUMBIEI 1.1. ORGANIZARE TERITORIALĂ Columbia (spaniolă Colombia), oficial Republica Columbia este o țară din partea de...

Introducere in econometrie Dezvoltarea rapida a econometriei a generat formularea mai multor definitii cu privire la domeniul acestei discipline...

1. Introducere – prezentarea variabilelor modelate Numărul salariaţilor din economie (mii pers.) În documentul realizat de Comisia Naţională...

CAPITOLUL I Piaţa asigurărilor de viaţă 1.1. Caracteristici generale ale pieţei asigurărilor Operaţiunile de asigurare realizate pe baze...

1 Analiza comerțului exterior folosind analiza econometrică 1.1 Culegerea datelor 2 Analiza modelului econometric folosind pachete de programe...