
Extras din referat
1. INTRODUCERE
Documentul de faţă descrie pe scurt ideea de a realiza un reportofon digital. Pe langă faptul că un astfel de aparat este destul de util a-l avea în preajmă pentru acele mici momente când ai nevoie de o confirmare ulterioara pentru cele întâmplate, poate servi drept o platforma bună pentru a testa diferite efecte ce pot fi aplicate asupra vocii umane pentru a-i modifica tonalitatea, înalţimea, tempo-ul.
Didactic este interesant deoarece familiarizeaza studentul cu diferite metode de a converti si stoca vocea umana din analog în digital, precum şi cu instrumentele disponibile pe microcontrollerul ATMEGA16 ce se preteaza unei astfel de întrebuinţari.
2. DESCRIERE GENERALA
Schema generala a reportofonului este prezentat mai jos.
După cum se vede din figură, echipamentul este format din mai multe etaje. Aceasta este datorată faptului că mecanismul transformării unui sunet analog în ceva digital si apoi recompunerea sa, se realizează în mai mulţi paşi ce vor fi explicaţi mai jos.
Achiziţia semnalului
Se bazează în principal pe colectarea unui semnal analogic de la un microfon şi supunerea sa unui proces de eşantionare şi filtrare. Aceste transformari ţin cont de anumite particularităţi ale vocii umane, si elimină astfel anumite caracteristici ale semnalului primit pentru a asigura o stocare si o redare cât mai eficientă. Se urmăreşte obţinerea la ieşire a unui sunet de o calitate asemănătoare celei telefonice.
Semnalul aflat la ieşirea microfonului poate fi descris ca o variaţie continuă, aparent aleatoare, a unei tensiuni X(t). Acesta va trebui să fie filtrat şi amplificat, astfel încat informaţia nerelevantă să dispară.
Vocea umană variază ca frecvenţă fundamentală între 85-155 Hz pentru bărbaţi, şi 165-255 Hz pentru femei. Ne va interesa ca sa inregistrăm atât frecvenţa fundamentală cât şi cele mai relevante armonice superioare pentru aceste frecvenţe. Studiile au stabilit că exista informaţie folosibilă pentru frecvenţe până la 3000 Hz. Astfel tot ce se va găsi mai sus de această frecvenţă va fi filtrat. Dupa ce am stabilit frecvenţa maxima ce ne interesează, vom calcula perioada de eşantionare folosind teorema Shannon.
Dacă nu se respectă legea de mai sus, armonicele semnalului primit se vor întrepătrunde, astfel încat identificarea lor şi recuperarea lor individuală nu se va mai putea realiza exact (fenomenul se numeşte aliasing).
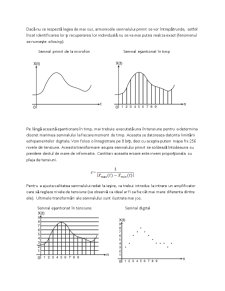
Semnal primit de la microfon Semnal eşantionat în timp
Pe lângă această eşantionare în timp, mai trebuie executată una în tensiune pentru a determina discret marimea semnalului la fiecare moment de timp. Aceasta se datoreaza datorita limitării echipamentelor digitale. Vom folosi o înregistrare pe 8 biţi, deci cu aceştia putem mapa fix 256 nivele de tensiune. Aceasta transformare asupra semnalului primit se soldează întodeauna cu pierdere destul de mare de informatie. Cantitaiv aceasta eroare este invers proporţionala cu plaja de tensiuni.
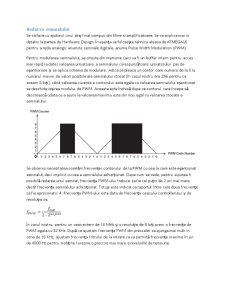
Pentru a ajusta calitatea semnalului redat la ieşire, va trebui introdus la intrare un amplificator care să regleze nivele de tensiune (se observă ca ideal ar fi sa fie cât mai mare diferenta dintre ele). Ultimele transformări ale semnalului sunt ilustrate mai jos.
Preview document


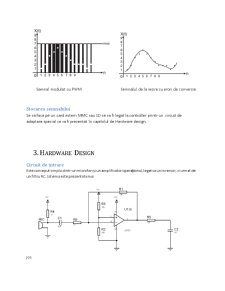



Conținut arhivă zip
- Inregistrare si Redare Sunet cu Stocare pe Card SD cu Atmega 16.doc